什么是机器学习?

我们已经讨论过数据标注或 数据标签 支持机器学习,并且它由标记或识别组件组成。 但至于深度学习和机器学习本身:机器学习的基本前提是计算机系统和程序可以以类似于人类认知过程的方式改进其输出,而无需人类的直接帮助或干预,从而为我们提供见解。 换句话说,他们变成了自我学习的机器,就像人类一样,通过更多的练习,他们的工作会变得更好。 这种“实践”是通过分析和解释更多(更好)的训练数据而获得的。
什么是数据标注?
数据标注是对数据进行归因、标记或标记的过程,以帮助机器学习算法理解和分类它们处理的信息。 此过程对于训练 AI 模型至关重要,使它们能够准确理解各种数据类型,例如图像、音频文件、视频片段或文本。
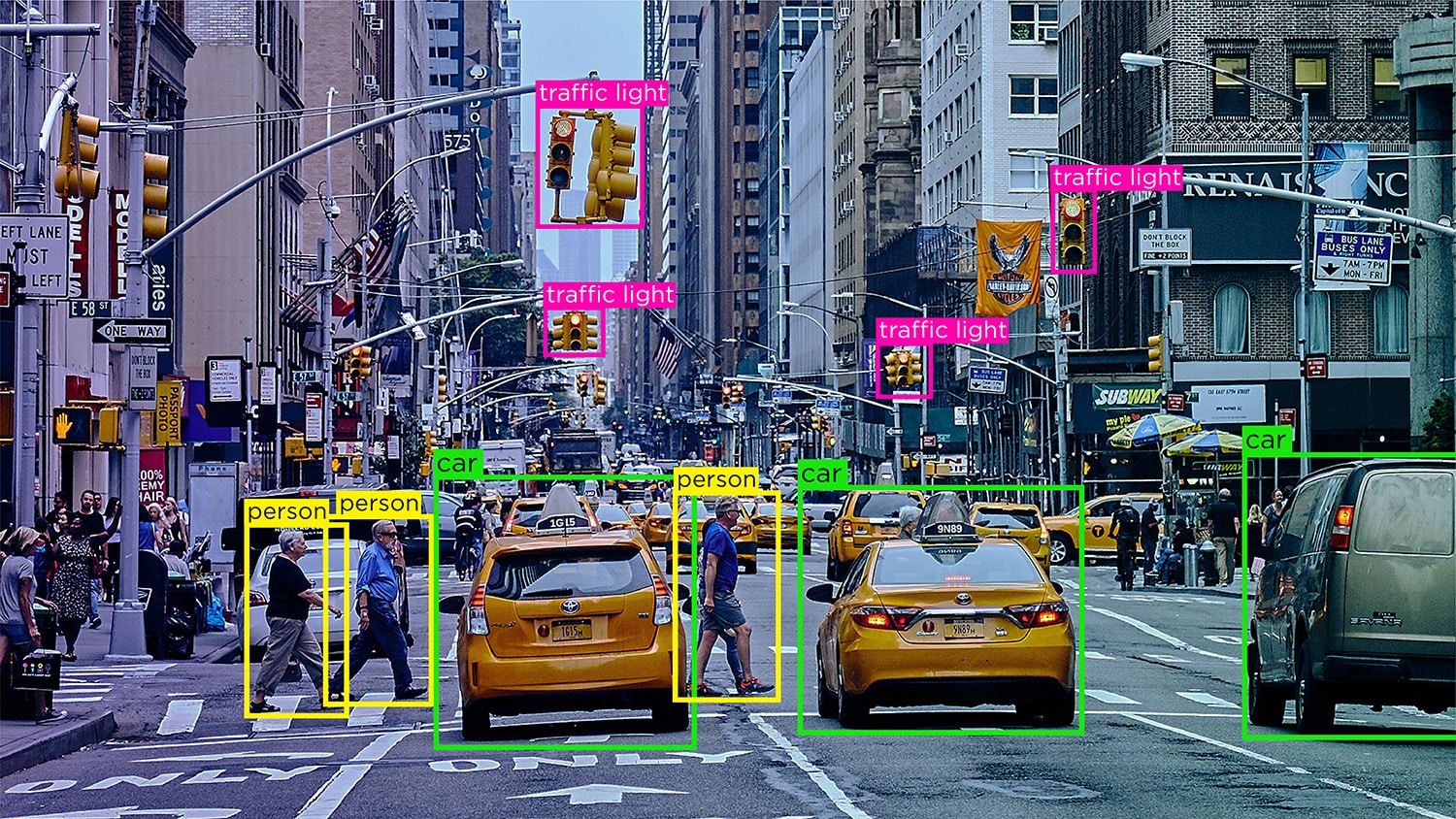
想象一下,一辆自动驾驶汽车依靠来自计算机视觉、自然语言处理 (NLP) 和传感器的数据来做出准确的驾驶决策。 为了帮助汽车的人工智能模型区分其他车辆、行人、动物或路障等障碍物,它接收到的数据必须被标记或标注。
在监督学习中,数据标注尤为重要,因为提供给模型的标记数据越多,它学习自主运行的速度就越快。 带标注的数据允许将 AI 模型部署在聊天机器人、语音识别和自动化等各种应用程序中,从而获得最佳性能和可靠结果。
数据标注在机器学习中的重要性
机器学习涉及计算机系统通过从数据中学习来提高性能,就像人类从经验中学习一样。 数据标注或标记在此过程中至关重要,因为它有助于训练算法识别模式并做出准确的预测。
在机器学习中,神经网络由分层组织的数字神经元组成。 这些网络处理类似于人脑的信息。 标记数据对于监督学习至关重要,监督学习是机器学习中的一种常见方法,算法从标记示例中学习。
使用标记数据训练和测试数据集使机器学习模型能够有效地解释和分类传入的数据。 我们可以提供高质量的标注数据来帮助算法自主学习并在最少的人工干预下对结果进行优先排序。
为什么需要数据标注?
我们知道一个事实,计算机能够提供不仅精确而且相关且及时的最终结果。 然而,机器如何学习以如此高效的方式交付?
这都是因为数据标注。 当机器学习模块仍在开发中时,它们会收到大量的 AI 训练数据,以使其更好地做出决策和识别对象或元素。
只有通过数据标注的过程,模块才能区分猫和狗,名词和形容词,或人行道上的道路。 如果没有数据标注释,机器的每张图像都是一样的,因为它们对世界上的任何事物都没有任何固有的信息或知识。
需要数据标注才能使系统提供准确的结果,帮助模块识别元素以训练计算机视觉和语音识别模型。 任何以机器驱动的决策系统为支点的模型或系统,都需要进行数据标注,以确保决策的准确性和相关性。