语义分割是计算机视觉中细粒度推理的基础条件之一,模型必须了解其所处的环境以达到所需的精度,因此,语义分割通过像素级精度为模型提供必备的条件。在这篇文章中,我们将讲述以下内容:
- 什么是语义分割?
- 语义分割和实例分割有什么不同?
- 语义分割的实战用例
- 语义分割的发展史
什么是语义分割?
语义分割的定义是对图像进行像素级别的分类和标注,比较容易和实例分割概念混淆,大体上的区别在于语义分割将所有同类物体进行相同的像素分类。
语义分割和实例分割有什么不同?
为了更清楚地解释他们的区别,图像分割是用来检测对象所属的类别,而实例分割顾名思义是给每个实例单独的唯一标签。简单来说:假如您要标注的图片中有多只绵羊,语义分割在检测图片中的对象时将多只绵羊分配同样的标签,都属于“绵羊”分类,而实例分割会给多只绵羊不同的分类。这两种方式都通过平滑地识别感兴趣对象在不同应用场景中发挥作用。在标注图像分割过程中,您需要根据任务类型的不同选择不同的标注方式。

语义分割的实战用例
语义分割可应用在以下常见场景中:
- 人脸识别
- 手写识别
- 图像搜索
- 自动驾驶
- 时尚行业虚拟试衣
- 卫星和航拍图像测绘
- 医疗成像和诊断
总而言之,相对于其他图像标注方式来说,语义分割是解决更复杂的任务的方法,让机器拥有更高水平的识别能力。继续阅读,我们将展开讲述语义分割的经典案例以进一步理解它。
语义分割的发展史
注:该段落转载自飞桨PaddlePaddle知乎账号。
Fully convolutional network(FCN)
J. Long et al. (2015) 首先将全卷积网络(FCN)应用于图像分割的端到端训练。FCN修改了VGG6等网络使其具有非固定大小的输入生成具有相同大小的分割图像,同时通过卷积层替换所有完全连接的层。由于网络生成具有小尺寸和密集表示的多个特征映射,因此需要进行上采样以创建相同大小的特征。基本上,它包含于一个步幅不小于1的卷积层。它通常称为反卷积,因为它创建的输出尺寸大于输入。这样的话,整个网络是基于像素点的损失函数进行训练的。此外,J. Long在网络中添加了跳过连接,以将高层级特征映射表示与网络顶层更具体和密集的特征表示相结合。FCN把CNN最后的全连接层换成卷积层,这也是其名字的由来。
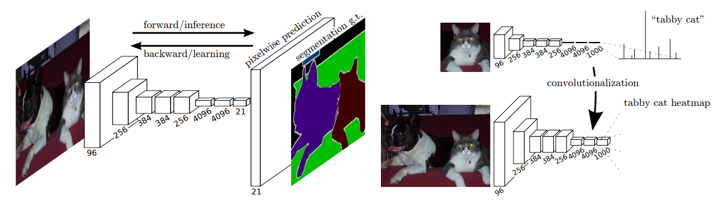
ParseNet
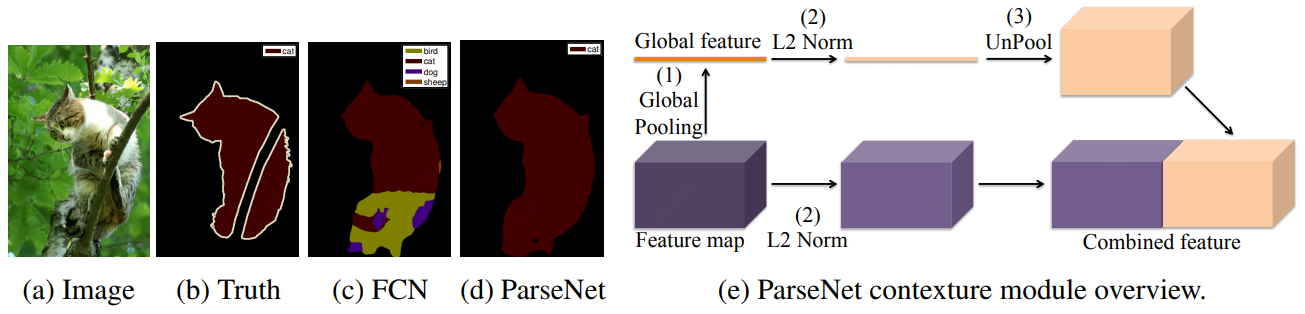
W. Liu et al. (2015) 针对J. Long的FCN模型进行了两步改进,第一步使用模型生成要素图,这些要素图被缩减为具有池化层的单个全局特征向量。使用L2欧几里德范式对该上下文向量进行归一化,并且将其取出(输出是输入的扩展版本)以生成具有与初始值相同的大小的新特征映射。第二步再使用L2 欧几里德范式对整个初始特征映射进行归一化。最后一步连接前两个步骤生成的要素图。规范化有助于缩放连接的要素图值,从而获得更好的性能。
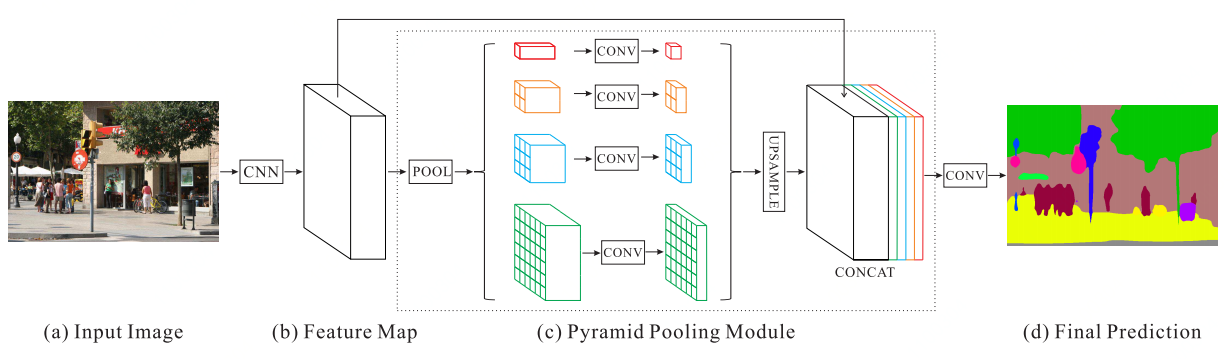
Pyramid Scene Parsing Network (PSPNet)
H. Zhao et al. (2016) 开发了金字塔场景解析网络(PSPNet),以更好地学习场景的全局内容表示。PSPNET使用具有扩张网络策略的特征提取器从输入图像中提取模式。特征提供给金字塔池化模块以区分具有不同比例的模式。它们与四个不同的尺度合并,每个尺度对应于金字塔等级,并由1×1卷积层处理以减小它们的尺寸。这样,每个金字塔等级分析具有不同位置的图像的子区域。金字塔等级的输出被上采样并连接到初始特征图以最终包含局部和全局的上下文信息。然后,它们由卷积层处理以生成逐像素的预测。
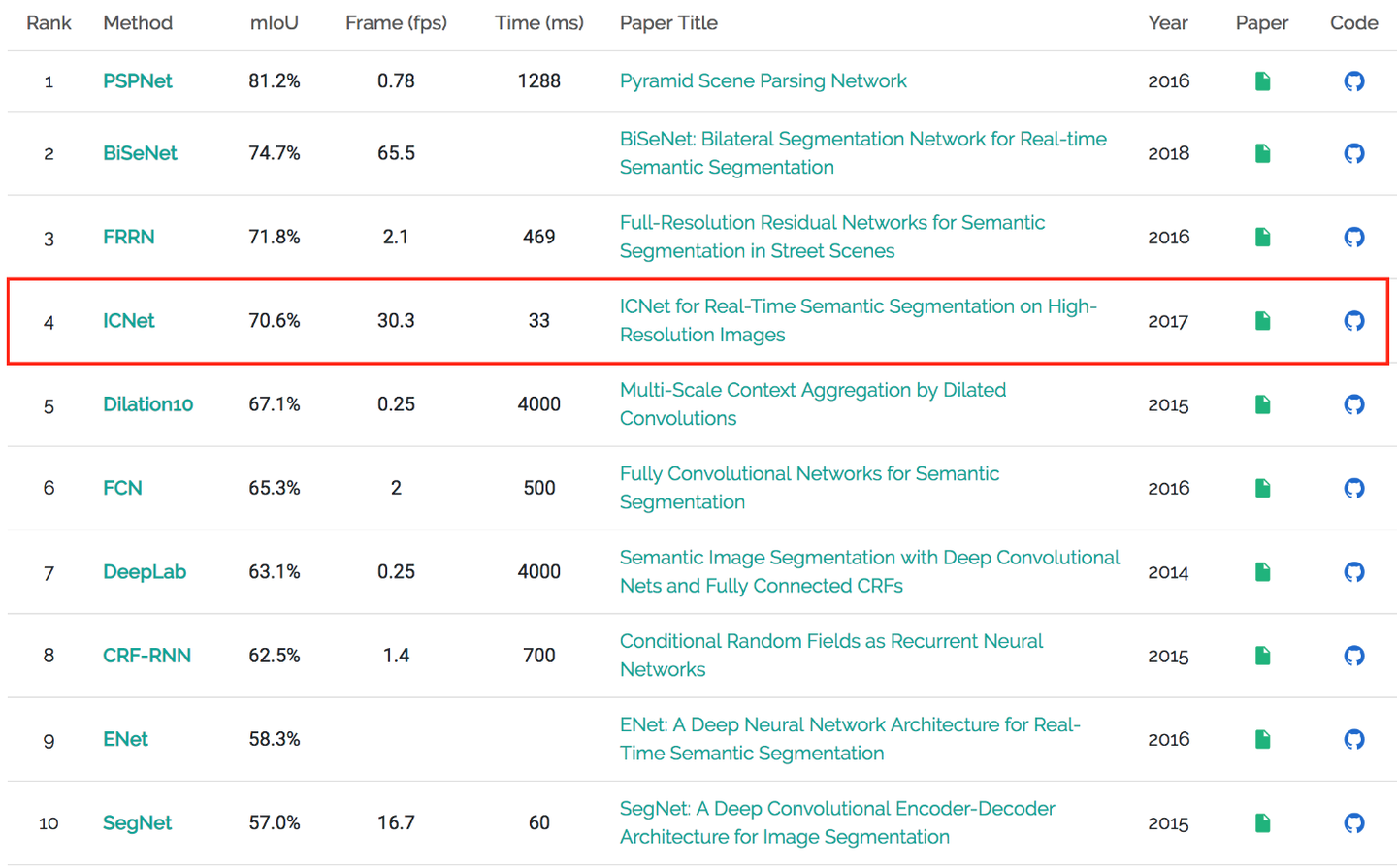
ICNET
H. Zhao et al. (2018)针对高清图像的实时语义分割,提出了一个基于PSPNet的图像级联网络(ICNET),它解决了现实应用中的基于像素标签推断需要大量计算的难题。ICNET可以在单块GPU卡上实现实时推断并在Cityscapes,CamVid等数据验证有相对不错的效果。
当今基于深度学习的各种网络架构不断提升图像语义分割的性能,但是都距离工业界的实际应用有一定距离,像在Cityscapes数据集取得不错效果的ResNet和PSPNet针对1024*1024的图像至少需要1秒钟做出推断,远远不能满足自动驾驶,在线视频处理,甚至移动计算等领域实时的要求,ICNET即是在这样的背景下,在不过多降低预测效果的基础上实现毫秒级相应以满足实时处理的要求。在Cityscapes数据集上,ICNET的响应时间可以达到33ms,处理能力达到30.3fps,准确率达到70.6%的mIoU分数。
ICNET的主要贡献在于开发了一种新颖独特的图像级联网络用于实时语义分割,它高效的利用了低分辨率的语义信息和高分辨率图像的细节信息;其中级联特征融合模块与级联标签引导模块能够以较小的计算代价完成语义推断,可以取得5倍的推断加速和5倍的内存缩减。
ICNET需要级联图像输入(即低,中和高)分辨率图像,采用级联特征融合单元(CFF)并基于级联标签指导进行训练。具有全分辨率的输入图像通过1/2和1/4比例进行下采样,形成特征输入到中分辨率和高分辨率的分支,逐级提高精度。
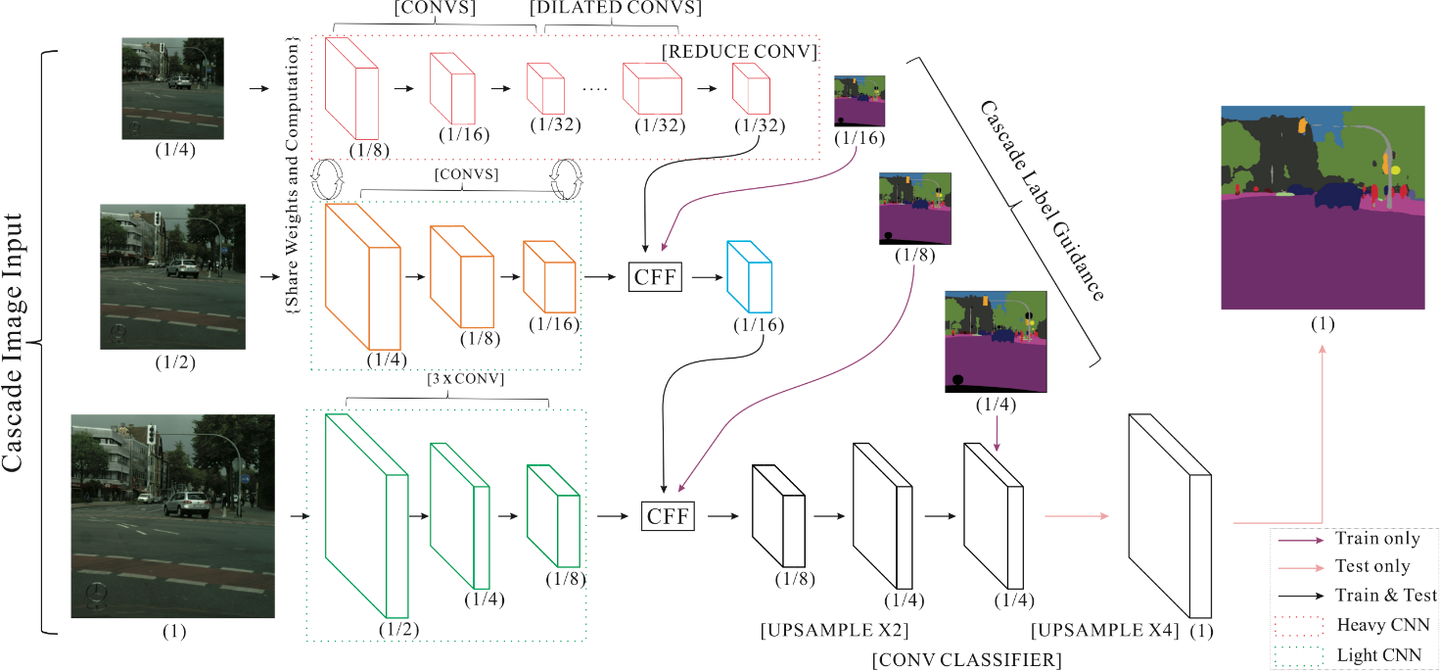
我们使用低分辨率输入得到语义提取,如上图顶部分支所示使用下采样率为8的比例将1/4大小的图像输入PSPNet,得到1/32分辨率的特征。获得高质量的分割,中高分辨率分支有助于恢复并重新处理粗糙的推断;CFF的作用就是引入中分辨率和高分辨率图像的特征,从而逐步提高精度,CFF的结构如下所示。
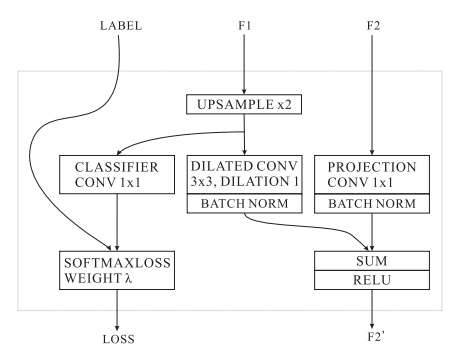
这样只有低分辨率的图像经过了最深的网络结构,而其他两个分支经过的层数都逐渐减少,从而提高了网络的速度。
为了降低网络的复杂度,ICNET采用了修剪网络每层中的内核来实现模型压缩。对于每个过滤器,首先计算内核L1范式的求和,然后降序排列仅保留部分排名靠前的内核。